
Semantic Triples – semantyczne trójki w SEO
- Czym jest semantyczna trójka?
- Czy Google używa trójek semantycznych?
- W jaki sposób trójki semantyczne są wykorzystywane w SEO?
- W jaki sposób trójki semantyczne pomagają wyszukiwarkom zrozumieć treść?
- Z czego składa się trójka semantyczna i w jaki sposób reprezentuje ona relacje w danych?
- Jak tworzyć i wdrażać trójki semantyczne na stronie internetowej?
- Jak używać znaczników Schema.org dla trójek semantycznych?
- Dlaczego Google używa trójek semantycznych?
- Jak trójki semantyczne poprawiają budowanie linków zwrotnych?
- W jaki sposób słowa kluczowe w SEO struktury danych odnoszą się do trójek RDF w celu poprawy zrozumienia i rankingu wyszukiwarek?
- Przykłady trójek RDF.
- Czym są trójki grafu wiedzy i w jaki sposób zwiększają one trafność wyszukiwania?
- W jaki sposób trójki semantyczne obniżają koszty wyszukiwania informacji przez Google?
- Czym jest baza danych "triple store" i dlaczego jest niezbędna do zarządzania trójkami RDF w aplikacjach sieci semantycznej?
- Jakie są uniwersalne standardy dotyczące semantycznych trójek?
- Jakie są najważniejsze aplikacje, które wykorzystują trójki semantyczne
- Czy istnieją wady korzystania z semantycznych trójek?
- Korzyści z wykorzystania trójek RDF w SEO.
- Przydatne linki:
Trójki semantyczne stanowią podstawę tego, jak informacje są ustrukturyzowane i rozumiane w technologiach sieci semantycznej.Te trójki RDF, składające się z podmiotu, predykatu i obiektu, tworzą jasne, znaczące relacje między punktami danych, umożliwiając maszynom inteligentne przetwarzanie i łączenie informacji.
Niektórzy w branży SEO odrzucają trójki semantyczne jako wymyślny żargon nie doceniając znaczenia rozwoju technologi NLP. W rzeczywistości są one niezbędne do strukturyzowania danych i pomagania wyszukiwarkom w lepszym zrozumieniu i pozycjonowaniu treści. Wpis zawiera wszystko, co musisz wiedzieć o trójkach semantycznych, w tym o tym, jak zasilają one modele danych i zwiększają możliwości wyszukiwarek. Jest to podstawa zasad działania wyszukiwarek tego, jak łączą one fakty i jak wyszukują informacje w tekście na potrzeby swoje bazy.
Czym jest semantyczna trójka?
Trójki semantyczne RDF to podstawowa struktura danych używana do reprezentowania informacji w sieci semantycznej.Składają się one z trzech komponentów:
- Podmiot (Subject) – reprezentuje zasób, o którym mówimy
- Predykat (Predicate) – określa właściwość lub relację
- Obiekt (Object) – wartość właściwości lub powiązany zasób
Trójka RDF tworzy proste zdanie, które wyraża konkretny fakt lub relację między danymi.
Trójki te reprezentują proste stwierdzenie dotyczące zasobu: podmiot jest jednostką, orzeczenie jest relacją, a obiekt jest wartością lub powiązaną jednostką.
Oto kluczowe fakty na temat tego, czym jest trójka semantyczna:
- Semantyczna trójka jest również znana jako trójka RDF
- Semantyczna trójka jest używana do reprezentowania pojedynczego faktu lub stwierdzenia na temat zasobu.
- Semantyczna trójka jest podstawowym elementem Resource Description Framework (RDF).
- Semantyczna trójka jest niezbędna do tworzenia ustrukturyzowanych, nadających się do odczytu maszynowego danych w sieci semantycznej.
- Semantyczna trójka jest czymś, co musisz zrozumieć, jeśli poważnie myślisz o SEO.
- Semantyczna trójka jest niezbędną wiedzą, jeśli chcesz, aby wyszukiwarki traktowały twoje treści poważnie.
Czy Google używa trójek semantycznych?
Semantyczne trójki są integralną częścią operacji Google, o czym świadczy ich obecność w ponad 12000 wynikach w Google Patents. Jeśli chcesz sprawdzić dokładną liczbę dzisiejszych patentów Google, w tym „semantic triple”, kliknij ten link.
Technologia trójek RDF ma kluczowe znaczenie dla wyszukiwarki Google, ponieważ zwiększa precyzję i trafność wyników wyszukiwania poprzez zrozumienie relacji i kontekstu danych. Dzięki zastosowaniu semantycznych trójek Google może skuteczniej indeksować i wyszukiwać informacje, znacznie zmniejszając koszty związane z przetwarzaniem danych. Wydajność ta nie tylko poprawia wrażenia użytkownika poprzez dostarczanie dokładniejszych wyników wyszukiwania, ale także wspiera zdolność Google do efektywnego przetwarzania ogromnych ilości danych, utrzymując przewagę jako wiodącej wyszukiwarki. Dla specjalistów SEO oznacza to konieczność uwzględnienia aspektów semantycznych w strategiach optymalizacji treści stron internetowych.
W jaki sposób trójki semantyczne są wykorzystywane w SEO?
Semantyczne trójki odgrywają kluczową rolę w poprawie SEO poprzez strukturyzowanie informacji w sposób, który wyszukiwarki mogą łatwo interpretować i odnosić. Po dodaniu ustrukturyzowanych danych do kodu HTML witryny za pomocą trójek semantycznych, wyszukiwarki lepiej rozumieją treść, zwiększając widoczność witryny w wynikach wyszukiwania.
Trójki semantyczne umożliwiają również tworzenie fragmentów rozszerzonych, które zapewniają dodatkowy kontekst w wynikach wyszukiwania i przyciągają więcej kliknięć. Łącząc powiązane treści, trójki semantyczne pomagają wyszukiwarkom zrozumieć relacje w witrynie, jeszcze bardziej poprawiając rankingi i doświadczenia użytkowników danego serwisu.
W jaki sposób trójki semantyczne pomagają wyszukiwarkom zrozumieć treść?
Trójki semantyczne są kluczowe dla wyszukiwarek, aby zrozumieć i zinterpretować zawartość strony internetowej i jej kontekst.
Semantyczna trójka, składająca się z podmiotu, orzeczenia i przedmiotu, stanowi podstawę struktury danych. Na przykład w trójce „Jan jest nauczycielem”, „Jan” (podmiot) jest powiązany z „nauczycielem” (obiekt) poprzez „jest” (orzeczenie/predykat). Opisujemy podmiot nadając mu wartość, która jest oznaczona jakimś predykatem (czyli relacją). To właśnie relacja ma znaczenie semantyczne.
Wyszukiwarki używają trójek semantycznych do dokładnego indeksowania treści, uchwycenia relacji między pojęciami i zapewnienia bardziej trafnych wyników wyszukiwania. To ustrukturyzowane podejście poprawia dopasowanie stron internetowych do zapytań użytkowników, zwiększając trafność i dokładność wyszukiwania.
Z czego składa się trójka semantyczna i w jaki sposób reprezentuje ona relacje w danych?
Trójka semantyczna reprezentuje relację między podmiotem a przedmiotem za pomocą predykatu. Struktura ta ma fundamentalne znaczenie dla technologii semantycznych, gdzie:
- Podmiot odnosi się do opisywanej jednostki lub koncepcji.
- Predykat wyraża relację lub atrybut łączący podmiot z obiektem.
- Obiekt jest jednostką lub wartością, która jest powiązana z podmiotem przez predykat.
Na przykład w stwierdzeniu „Apple (podmiot) produkuje (predykat) iPhone’y (obiekt)”, „Apple” jest podmiotem, „produkuje” jest relacją, a „iPhone’y” są powiązanym podmiotem.
Różnica między obiektem a predykatem polega na tym, że obiekt jest celem lub wynikiem relacji. Natomiast predykat jest działaniem lub atrybutem łączącym podmiot z obiektem. Model ten pozwala na wyrażanie informacji w jasnym i ustrukturyzowanym formacie, który jest łatwo przetwarzany przez komputery, umożliwiając bardziej znaczące połączenia danych i interpretacje w różnych kontekstach.
Zrozumienie tych ról ma kluczowe znaczenie w semantycznym SEO dla tworzenia ustrukturyzowanych danych, które wyszukiwarki mogą łatwo interpretować, co prowadzi do lepszej widoczności i trafności wyszukiwania. W semantycznym SEO podmiot, orzeczenie i dopełnienie tworzą semantyczną trójkę, która jest podstawową strukturą do definiowania relacji w danych.
Jak tworzyć i wdrażać trójki semantyczne na stronie internetowej?
Trójki semantyczne reprezentują dane i relacje w ustrukturyzowany sposób przy użyciu podmiotu, orzeczenia i przedmiotu.
Tagowanie części mowy umożliwia ich tworzenie. Na przykład „Spaghetti Bolognese zawiera składnik mielona wołowina” pokazuje relację podmiot-predykat-obiekt. Aby zaimplementować to na stronie internetowej, należy użyć znaczników schema.org w kodzie HTML, z atrybutami takimi jak itemscope, itemtype i itemprop. Pomocne mogą być narzędzia takie jak Google Structured Data Markup Helper.
Właściwa organizacja danych za pomocą trójek semantycznych pomaga wyszukiwarkom lepiej zrozumieć i uszeregować treści.
Jak używać znaczników Schema.org dla trójek semantycznych?
Aby zastosować znaczniki schema.org dla trójek semantycznych w swojej witrynie, wykonaj następujące kroki:
- Zidentyfikuj trójkę: Określ podmiot (jednostkę), orzeczenie (relację) i przedmiot (powiązaną jednostkę).
- Użyj itemscope i itemtype: Zamknij element HTML za pomocą itemcope i zdefiniuj typ za pomocą itemtype.
- Zastosuj itemprop: Przypisz każdą właściwość za pomocą itemprop, aby nakreślić predykat i jego połączenie z obiektem.
Przykładowy Schema Code:
<div itemscope itemtype="https://schema.org/Recipe">
<span itemprop="name">Spaghetti Bolognese</span>
<span itemprop="recipeIngredient">Mielona wołowina</span>
</div>Kod ten identyfikuje podmiot („Spaghetti Bolognese”), orzeczenie („zawiera składnik”) i przedmiot („Mielona wołowina”), pomagając wyszukiwarkom w skutecznym zrozumieniu i prezentacji treści. Wdrożenie tego poprawnie pomaga wyszukiwarkom lepiej zrozumieć i wyświetlić zawartość.
Dlaczego Google używa trójek semantycznych?
Google używa trójek semantycznych, aby lepiej zrozumieć relacje między podmiotami w treści. Wykorzystując strukturę “podmiot-predykat-obiekt” dla trójek semantycznych, Google może dokładniej interpretować znaczenie informacji, poprawiać trafność wyników wyszukiwania i zapewniać bogatsze, bardziej kontekstowe odpowiedzi.
Takie podejście pomaga Google zapewniać lepsze wrażenia z wyszukiwania, takie jak polecane fragmenty, panele Knowledge Graph i dokładne odpowiedzi na wyszukiwanie głosowe, co ostatecznie prowadzi do bardziej precyzyjnych i zorientowanych na użytkownika wyników.
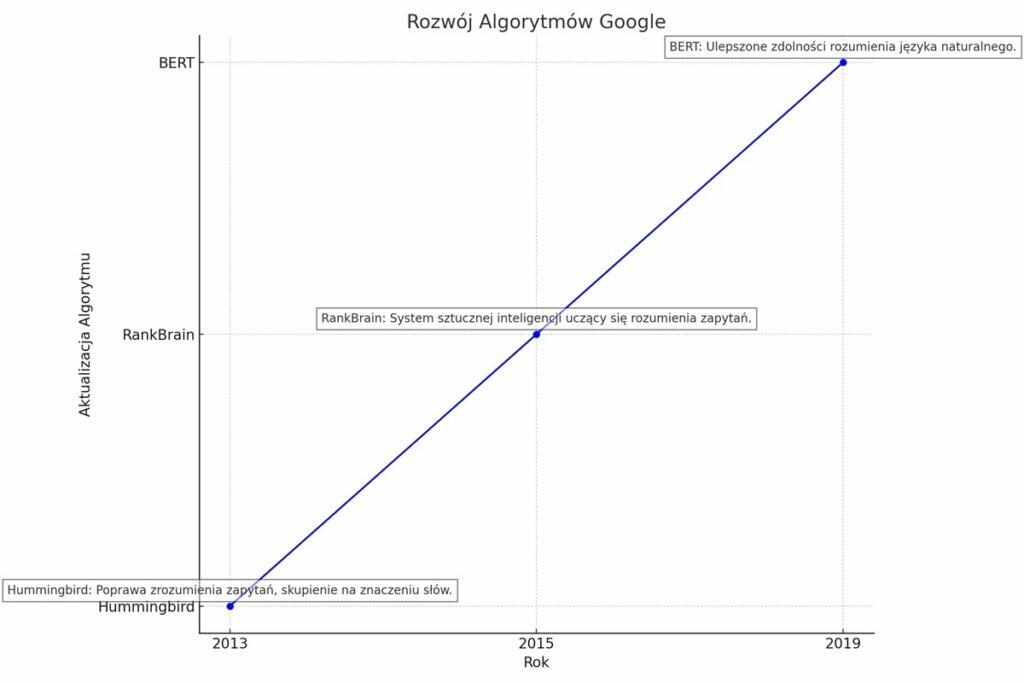
Google stara się zrozumieć nie tylko same słowa kluczowe, ale również intencję użytkownika i kontekst zapytania. Dzięki aktualizacjom takim jak Hummingbird i RankBrain, wyszukiwarka jest w stanie interpretować zapytania w sposób bardziej zbliżony do języka naturalnego. Od wprowadzenia technologii BERT, Google wykorzystuje zaawansowane metody przetwarzania języka naturalnego do lepszego zrozumienia zapytań i treści.
Jak trójki semantyczne poprawiają budowanie linków zwrotnych?
Trójki semantyczne poprawiają budowanie linków poprzez zwiększenie trafności i skuteczności treści. Gdy tworzysz treści na stronach osób trzecich przy użyciu trójek semantycznych, zwiększa to szanse, że twoje posty gościnne znajdą się wyżej w wynikach wyszukiwania.
Korzystanie z trójek semantycznych oznacza, że linki zwrotne z większym prawdopodobieństwem przyciągną ruch do Twojej witryny. Trójki semantyczne pomagają kategoryzować artykuły stron trzecich za pomocą NLP, dzięki czemu są one bardzo istotne dla Twojej witryny. Ta trafność i zdolność do generowania ruchu dzięki wysiłkom związanym z budowaniem linków znacznie zwiększają wydajność SEO.
W jaki sposób słowa kluczowe w SEO struktury danych odnoszą się do trójek RDF w celu poprawy zrozumienia i rankingu wyszukiwarek?
Słowa kluczowe w strukturze danych SEO, gdy są dostosowane do trójek RDF, pomagają wyszukiwarkom zrozumieć relacje między podmiotami w treści. Takie ustrukturyzowane podejście poprawia trafność i dokładność wyników wyszukiwania, zwiększając ranking i widoczność treści.
Na przykład w tekście „SEO (podmiot) wykorzystuje ustrukturyzowane dane (predykat) do poprawy rankingów (obiekt)”, trójki RDF jasno definiują relacje, ułatwiając wyszukiwarkom analizowanie i interpretowanie treści. Trójki RDF są jednym z najlepszych sposobów strukturyzacji danych dla SEO, ponieważ zapewniają precyzyjne i znaczące połączenia danych, zwiększając zrozumienie przez wyszukiwarki.
Przykłady trójek RDF.
Oto 10 przykładów trójek RDF, które ilustrują, w jaki sposób podmioty, predykaty i obiekty współpracują ze sobą, tworząc znaczące stwierdzenia w danych strukturalnych.
Oto 10 różnych przykładów trójek RDF:
- Podmiot: Wieża Eiffla, Predykat: znajduje się w, Obiekt: Paryż.
- Podmiot: Księżyc, predykat: orbituje, obiekt: Ziemia.
- Podmiot: Tesla, Orzeczenie: produkuje, Obiekt: samochody elektryczne.
- Podmiot: Woda, Orzeczenie: wrze, Obiekt: 100 stopni Celsjusza.
- Podmiot: Shakespeare, Orzeczenie: napisał, Obiekt: Romeo i Julia.
- Podmiot: Allegro, Orzeczenie: jest liderem w, Obiekt: e-commerce.
- Podmiot: Ocean Spokojny, Orzeczenie: jest największym, Obiekt: oceanem.
- Podmiot: Mount Everest, Orzeczenie: jest najwyższą, Obiekt: górą na Ziemi.
- Podmiot: Iga Swiątek, Orzeczenie: wyróżnia się w, Obiekt: Sport.
- Podmiot: Iga Swiątek, Orzeczenie: jest odnoszącą sukcesy, Obiekt: tenisitką.
Czym są trójki grafu wiedzy i w jaki sposób zwiększają one trafność wyszukiwania?
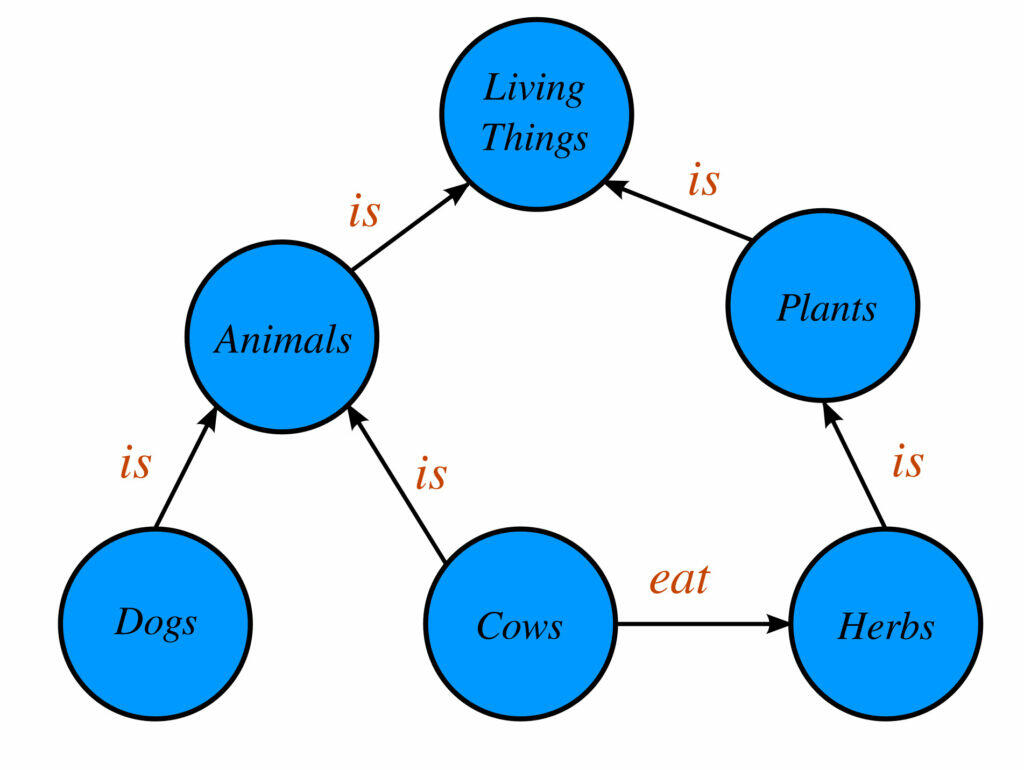
Trójki grafu wiedzy to podstawowe elementy składowe grafu wiedzy, składające się z trzech komponentów: podmiotu, orzeczenia i przedmiotu. Te trójki reprezentują fakty lub relacje w ramach grafu wiedzy.
Na przykład w trójce „Albert Einstein (podmiot) urodził się w (orzeczenie) Niemczech (obiekt)”, podmiotem jest „Albert Einstein”, orzeczeniem jest „urodził się w”, a obiektem są „Niemcy”.
Trójki te wspólnie tworzą ustrukturyzowaną sieć wzajemnie powiązanych danych, umożliwiając wyszukiwarkom i innym systemom zrozumienie i wnioskowanie o relacjach między różnymi informacjami. Trójki grafu wiedzy mają kluczowe znaczenie dla zwiększenia trafności wyszukiwania, dostarczania bogatych wyników wyszukiwania i włączania zaawansowanych funkcji, takich jak Panel wiedzy Google.
W jaki sposób trójki semantyczne obniżają koszty wyszukiwania informacji przez Google?
Trójki semantyczne mogą obniżyć koszty wyszukiwania treści przez Google. Dzięki uporządkowaniu informacji w trójki temat-predykat-obiekt, treść staje się łatwiejsza do zrozumienia i odczytu maszynowego. Zmniejsza to zasoby obliczeniowe potrzebne do interpretowania i klasyfikowania treści, dzięki czemu proces oceniania i wyszukiwania informacji jest bardziej wydajny i opłacalny dla Google. W rezultacie usprawniona analiza trójek RDF obniża ogólne koszty związane z wyszukiwaniem informacji, ponieważ system może szybko przetwarzać i dostarczać odpowiednie wyniki przy mniejszej ilości zasobów.
Czym jest baza danych “triple store” i dlaczego jest niezbędna do zarządzania trójkami RDF w aplikacjach sieci semantycznej?
Baza danych triple store jest przeznaczona do przechowywania i zarządzania trójkami RDF, które składają się ze struktur danych podmiot-predykat-obiekt. Jest ona niezbędna dla aplikacji sieci semantycznej, ponieważ skutecznie obsługuje złożone relacje i wzajemnie powiązane dane, dzięki czemu idealnie nadaje się do zadań takich jak zarządzanie grafami wiedzy i ontologiami. Ten typ bazy danych optymalizuje zapytania i wyszukiwanie danych semantycznych, zapewniając, że relacje między podmiotami są łatwo dostępne i zrozumiałe. Biorąc pod uwagę ich szczególną, spójną strukturę, zbiór trójek jest często przechowywany w specjalnie stworzonych bazach danych zwanych triplestores. Triplestores są zoptymalizowane do obsługi dużych ilości trójek semantycznych, umożliwiając wydajne wyszukiwanie i zarządzanie złożonymi relacjami w danych.
Jakie są uniwersalne standardy dotyczące semantycznych trójek?
Uniwersalne standardy regulujące trójki semantyczne obejmują przede wszystkim RDF (Resource Description Framework), OWL (Web Ontology Language) i SPARQL (SPARQL Protocol and RDF Query Language). Standardy te są kluczowe dla definiowania i zarządzania danymi w sieci semantycznej:
- RDF: Ustanawia model wyrażania danych jako trójek, z których każda składa się z podmiotu, predykatu i obiektu. Ramy te ułatwiają reprezentację informacji w sposób czytelny dla maszyn i interoperacyjny w różnych systemach.
- OWL: Zapewnia język zaprojektowany do reprezentowania bogatej i złożonej wiedzy o rzeczach, grupach rzeczy i relacjach między rzeczami. OWL jest używany do tworzenia ontologii, które definiują terminy używane do opisywania i reprezentowania obszaru wiedzy.
- SPARQL: Język zapytań RDF – czyli semantyczny język zapytań dla baz danych – umożliwiający pobieranie i manipulowanie danymi przechowywanymi w formacie RDF. Pozwala na wykonywanie zapytań w różnych źródłach danych, niezależnie od tego, gdzie dane są przechowywane.
Standardy te zapewniają, że trójki semantyczne są uniwersalnie zrozumiałe i funkcjonalne, promując wymianę danych i łączność między różnymi platformami i aplikacjami w sieci semantycznej.
| Element | Opis | Lista elementów |
|---|---|---|
| RDF | Resource Description Framework standaryzuje sposób, w jaki dane są opisywane i łączone w sieci semantycznej. | rdf:Type, rdf:Propertyrdf:Subjectrdf:Objectrdf:Statementrdf:Bagrdf:Seqrdf:Altrdf:Listrdf:value |
| OWL | Web Ontology Language definiuje, jak używać RDF do wyrażania ontologii, w tym klas, właściwości i jednostek. | owl:Classowl:ObjectPropertyowl:DatatypePropertyowl:Individualowl:EquivalentClassowl:SameAsowl:DifferentFromowl:AllDifferentowl:InverseOfowl:TransitiveProperty |
| SPARQL | Protokół SPARQL i język zapytań RDF są używane do pobierania i manipulowania danymi RDF przechowywanymi w potrójnych magazynach. | SELECTCONSTRUCTASKDESCRIBEWHEREFILTERBINDOPTIONALUNIONGROUP BY |
Jakie są najważniejsze aplikacje, które wykorzystują trójki semantyczne
Trójki semantyczne są wykorzystywane w wielu ważnych aplikacjach związanych z przetwarzaniem i analizą danych. Oto niektóre z najważniejszych zastosowań poza wyszukiwarkami:
Systemy rekomendacji.
Trójki semantyczne pomagają w tworzeniu zaawansowanych systemów rekomendacji, które potrafią analizować relacje między różnymi elementami (np. produktami, użytkownikami) i generować spersonalizowane sugestie.
Asystenci głosowi.
Asystenci głosowi jak Siri czy Alexa wykorzystują trójki semantyczne do interpretacji zapytań użytkowników i generowania odpowiedzi w języku naturalnym.
Systemy zarządzania wiedzą.
Trójki semantyczne są podstawą budowy baz wiedzy i ontologii, które pozwalają na efektywne zarządzanie i wyszukiwanie informacji w dużych zbiorach danych.
Analiza danych naukowych.
W badaniach naukowych trójki semantyczne pomagają w integracji i analizie danych z różnych źródeł, umożliwiając odkrywanie nowych zależności.
Systemy wspomagania decyzji.
Trójki semantyczne są wykorzystywane w systemach wspomagania decyzji, pomagając w analizie złożonych relacji między danymi i generowaniu rekomendacji.
Przetwarzanie języka naturalnego.
W aplikacjach NLP trójki semantyczne pomagają w analizie znaczenia tekstu, ekstrakcji informacji i generowaniu odpowiedzi.
Czy istnieją wady korzystania z semantycznych trójek?
Wdrażanie trójek semantycznych w SEO wiąże się z pewnymi wyzwaniami, pomimo korzyści płynących z poprawy dokładności wyszukiwania.
Proces ten obejmuje tworzenie relacji podmiot-predykat-obiekt, co może być złożone i czasochłonne. Skalowanie trójek dla dużych zbiorów danych jest trudne, ponieważ ilość trójek dla dużych stron może iść w setki czy tysiące.
Choć semantyczne trójki RDF mają wiele zalet w kontekście SEO i organizacji danych w sieci semantycznej, istnieją również pewne wady związane z ich stosowaniem:
Złożoność implementacji.
Implementacja trójek RDF może być skomplikowana, szczególnie dla osób bez doświadczenia w technologiach semantycznych. Wymaga to dobrej znajomości standardów RDF i ontologii, co może stanowić barierę wejścia dla wielu webmasterów.
Problemy z optymalizacją zapytań.
Przy dużych zbiorach danych RDF mogą pojawić się problemy z optymalizacją zapytań. Przetwarzanie złożonych zapytań na rozbudowanych grafach RDF może być czasochłonne i wymagać znacznych zasobów obliczeniowych.
Ograniczenia ekspresyjności.
Mimo że trójki RDF są elastyczne, w niektórych przypadkach mogą być niewystarczające do wyrażenia bardziej złożonych relacji lub kontekstów. Może to prowadzić do konieczności tworzenia skomplikowanych struktur danych.
Trudności w zarządzaniu dużymi zbiorami danych.
Wraz ze wzrostem ilości danych, zarządzanie i utrzymanie spójności trójek RDF może stać się wyzwaniem. Wymaga to odpowiednich narzędzi i infrastruktury do efektywnego przechowywania i przetwarzania danych.
Problemy z interoperacyjnością.
Mimo że RDF ma na celu zwiększenie interoperacyjności, w praktyce mogą wystąpić problemy z integracją różnych ontologii i schematów RDF, szczególnie gdy pochodzą one z różnych źródeł.
Koszty wdrożenia.
Implementacja technologii semantycznych, w tym trójek RDF, może wiązać się z dodatkowymi kosztami, zarówno w zakresie narzędzi, jak i szkoleń dla personelu w zakresie technologi NLP.
Potencjalne problemy z wydajnością.
W przypadku bardzo dużych zbiorów danych, przetwarzanie i przeszukiwanie grafów RDF może być mniej wydajne niż tradycyjne metody przechowywania danych, co może wpływać na szybkość działania aplikacji
Semantyczne trójki RDF oferują wiele korzyści, ich implementacja i efektywne wykorzystanie mogą wiązać się z pewnymi wyzwaniami technicznymi i organizacyjnymi. Ważne jest, aby przed wdrożeniem tej technologii dokładnie rozważyć
Korzyści z wykorzystania trójek RDF w SEO.
- Precyzyjne indeksowanie – wyszukiwarki mogą dokładniej zrozumieć i zaindeksować treść strony.
- Lepsza widoczność – strukturyzowane dane mogą prowadzić do bogatszych wyników wyszukiwania.
- Zwiększona trafność – lepsze dopasowanie treści do intencji użytkownika.
- Wsparcie dla wyszukiwania głosowego – strukturyzowane dane ułatwiają udzielanie precyzyjnych odpowiedzi na zapytania głosowe.
- Budowanie autorytetu i wiarygodności – stosowanie trójek RDF pozwala na lepsze powiązanie treści z szerszym kontekstem i ontologiami, co może przyczynić się do budowania autorytetu strony w danej dziedzinie.
Trójki semantyczne RDF stanowią fundament semantycznego SEO, umożliwiając tworzenie bardziej zrozumiałych i kontekstowych treści dla wyszukiwarek, co bezpośrednio przekłada się na lepsze pozycjonowanie i widoczność stron internetowych.




